Course Description
This course will help you understand how Hadoop, Spark and its eco-system solves storage and processing of large data sets in a distributed environment.












Interview Preparation Kit

Interview Preparation Kit
Interview Preparation Kit

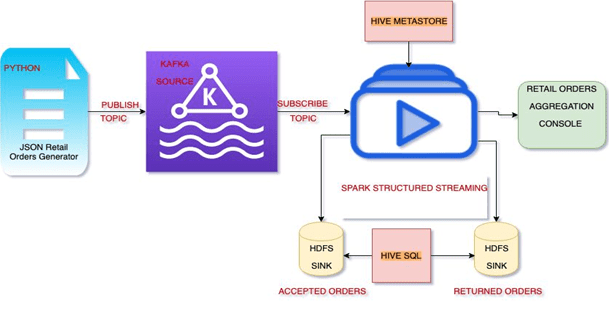
The purpose of the project is to subscribe to KAFKA topic from spark structured streaming read stream API and the JSON records are generated automatically using the python retail data generator script. We use HDFS sink of CSV format to write the accepted orders and rejected orders to different location in HDFS and the aggregation of orders like average amount and the count of order Quantity is written to the console. The hive tables orders and orders reject is used to query the accepted and rejected retails orders.
The purpose of this project is to dynamically allocate resources for a Hive job at run time. The job details are present in a XML file read during execution. Based on the job name present in the XML file, the business logic lookup a XML file with the matching job name and assign dynamically the hive job a Queue in capacity scheduler , set multiple resource values and start running the job and the job execution status is visible in Hadoop resource manager Web UI.

1. You have to transfer Rs.1000 towards the registration amount to the below mentioned account details
2. Send screen shot of the payment to info@www.npntraining.com with subject as “Big Data Data Masters Program Pre Registration
3. Once we receive payment , we will be acknowledging the payment through our official email id..
Account Details
| Name: | Naveen P.N |
| Bank Name | State Bank Of India |
| Account No | 64214275988 |
| Account Type | Current Account |
| IFSC Code | SBIN0040938 |
| Bank Branch | Ramanjaneya Nagar |
Send screen shot to : info@www.npntraining.com
Email Subject: Big Data Masters Program Pre Registration
Registration Fees: Rs.1000
Note : Check for the batch availability with Naveen sir before doing the pre-registration.
Sorry  Due to Covid situation we are not offering classroom training at present.
Due to Covid situation we are not offering classroom training at present.